robots.txt - Steuerung des Crawling-Verhaltens für SEO
Die Datei robots.txt ist ein wichtiges Werkzeug zur Steuerung des Suchmaschinen-Crawlings. Sie gibt Web-Crawlern wie dem Googlebot Anweisungen, welche Bereiche Ihrer Website von Crawlern besucht werden dürfen und welche nicht. In diesem Artikel erfahren Sie, wie Sie robots.txt korrekt einsetzen, häufige Fehler vermeiden und dadurch Ihre SEO-Performance optimieren.

Was ist die robots.txt-Datei?
Die robots.txt-Datei ist eine einfache Textdatei, die sich im Root-Verzeichnis einer Website befindet, z. B. www.beispiel.de/robots.txt. Sie dient als erste Anlaufstelle für Suchmaschinen-Crawler und gibt ihnen Anweisungen, welche Seiten sie besuchen dürfen und welche nicht.
Die Datei Robots.txt steuert somit das Crawling durch Suchmaschinen, und nicht direkt die Indexierung. Sie hilft, dass die Bots nicht zu viel Zeit mit unwichtigen oder doppelten Seiten verbringen. Eine fehlerhafte Konfiguration kann dazu führen, dass die Bots wichtige Seiten nicht besuchen und diese deshalb nicht indexiert werden.
Bei den Direktiven in der robots.txt handelt es sich lediglich um Empfehlungen, es gibt keine Garantien, dass sich die Crawler auch an die Vorgaben halten. Die meisten Suchmaschinen beachten jedoch die Vorgaben.

Syntax und Aufbau
Die robots.txt-Datei besteht aus einer Reihe von Direktiven, die den Crawlern mitteilen, welche Bereiche der Website sie besuchen dürfen. Eine typische robots.txt-Struktur zeigt das Bild.
Die Datei verbietet allen Crawlern (User-agent: *) den Zugriff auf das Verzeichnis /intern/, erlaubt jedoch den Besuch einer bestimmten Datei in dem Verzeichnis /intern/öffentliche-seite.html.
Direktiven in der robots.txt
Die Anweisungen in einer robots.txt beeinflussen das Verhalten von Crawlern. Die Hauptdirektiven sind folgende:
- User-agent: Gibt an, für welchen Suchmaschinenbot die Regel gilt (z. B. Googlebot, Bingbot).
- Disallow: Verbietet das Crawling bestimmter Seiten oder Verzeichnisse.
- Allow: Ist eine Ausnahme von Ausschlüssen, erlaubt explizit den Zugriff auf bestimmte Inhalte, wenn das übergeordnete Verzeichnis gesperrt ist.
- Sitemap: Verweist auf die XML-Sitemap, um Suchmaschinen bei der Indexierung zu helfen.
Anwendungsfälle aus der SEO-Praxis

Beispiel für eine gezielte Steuerung
In dieser robots.txt wird nur Googlebot der Zugriff auf /admin/ untersagt, jedoch der Zugriff auf die Datei /public-info.html in demselben Verzeichnis ist explizit per Allow erlaubt.
Zudem gibt es den Verweis auf die Sitemap, damit die Suchmaschinen relevante Seiten leichter finden.

Ausschluss sensibler oder irrelevanter Inhalte
Nicht alle Seiten einer Website sind für Suchmaschinen relevant. Beispielsweise werden interne Login-Seiten, Suchergebnisseiten, Seiten im Backend-Bereich, Warenkorb-/Checkout-Seiten, temporäre Dateien oder reine Formularseiten vom Crawling ausgeschlossen.
In diesem Beispiel sind Login- und Suchergebnisseiten vom Crawling ausgeschlossen.

Steuerung des Crawl-Budgets bei großen Websites
Große Websites mit vielen tausend Unterseiten haben ein begrenztes Crawl-Budget – also eine bestimmte Anzahl von Seiten, die der Googlebot pro Besuch crawlt. Durch eine optimierte robots.txt lässt sich sicherstellen, dass die Crawler nur wichtige Inhalte erfassen und unwichtige oder doppelte Seiten ignorieren.
Diese robot-txt verhindert, dass Crawl-Budget für unwichtige temporäre oder veraltete Archiv-Seiten verschwendet wird.

Umgang mit dynamischen URLs und Filtern
Online-Shops oder Blogs erzeugen oft zahlreiche dynamische URLs durch Filter oder Sortierungen,
z. B. ?sort=preis-aufsteigend. Solche URLs führen zu doppeltem Inhalt und unnötigem Crawling.
Eine Lösung ist es, diese Parameter zu blockieren. Diese robots.txt schließt alle URLs mit den Parametern ?sort= und &filter= vom Crawling aus.
Typische Fehler in der robots.txt
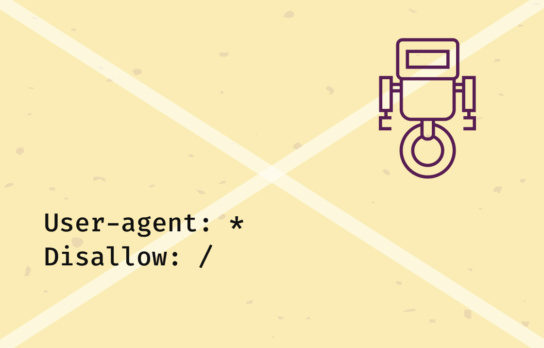
Fehlerhafte Blockierung wichtiger Seiten
Ein häufiger Fehler ist das unbeabsichtigte Sperren ganzer Websites. Zum Beispiel verhindert folgende Konfiguration, dass eine Website in Google erscheint.
Die Anweisung in der robot.txt verbietet allen Crawlern den Zugriff auf sämtliche Seiten. Falls dies aus Versehen passiert, kann es zum kompletten Verlust der Rankings führen.

Verzeichnisse mit Allow freigeben
Falls Disallow: / definiert ist, lassen sich wichtige Verzeichnisse explizit mit Allow freigeben.
Best Practices
- Indexierung vermeiden: Robots.txt steuert nur das Crawling, nicht die Indexierung. Es kann durchaus sein, dass gesperrte Inhalte dennoch im Index landen, z.B. durch viele Backlinks auf eine URL. Falls eine Seite nicht im Index erscheinen soll, müssen Sie ein noindex-Tag im HTML-Header der Seiten setzen.
- Regelmäßige Überprüfung: Prüfen Sie die Datei über das robots.txt-Tester-Tool in der Search Console unter Einstellungen/robots.txt. Gibt es Probleme mit der robots.txt, werden diese dort angezeigt.
- Regelmäßige Anpassungen: Änderungen in der Website-Struktur sollten Sie stets in der robots.txt berücksichtigen.
Fazit
Die robots.txt-Datei ist ein leistungsstarkes SEO-Werkzeug zur Steuerung des Suchmaschinen-Crawlings. Sie hilft dabei, irrelevante oder sensible Inhalte auszuschließen, das Crawl-Budget effizient zu nutzen und doppelte Inhalte zu ignorieren.
Durch eine sorgfältige Konfiguration und regelmäßge Überprüfung können Sie sicherstellen, dass die Suchmaschinen die relevanten Inhalte Ihrer Website erfassen und im besten Falle indexieren.
Mehr lesen!
Bleiben Sie auf dem Laufenden mit unserem Blog.

Auch interessant!
Überzeugen Sie sich von unseren Leistungen.
